Iterating Statistical Driver Values: DriverSequence
Introduction
Instances of DriverSequence class generate sequences of
double numbers by drawing values sequentially from
a stored list. Values range from zero to unity.
The Sequence.UsageMode enumeration identifies
four ways of using DriverSequence (and also four ways of using
IndexSequence, but these have different
implications).
-
UsageMode.UNIQUE_DIRECTstores driver values in order from lowest (near zero) to highest (near unity). This is the most rudimentary mode. When thesamplingOffsetis 0 and thesamplingIncrementis 1,IndexSequencegenerates drivers in ascending order. When thesamplingOffsetis -1 and thesamplingIncrementis -1,IndexSequencegenerates drivers in descending order. In practice, I have only ever used this mode to generate graphs showing how classes implementing theTransforminterface map driver values to targets in the distribution range. -
UsageMode.UNIQUE_SHUFFLEDinitially stores drivers in order from lowest (near zero) to highest (near unity); however, their presentation order is shuffled randomly prior to each new cycle. This insures that the list of values is fully expressed over a cycle. In practice,samplingOffsetshould always be 0, whilesamplingIncrementshould always be 1 (nothing else makes sense owing to shuffling). -
UsageMode.SAMPLES_DIRECTstores driver values obtained from an external source. When thesamplingOffsetis 0 and thesamplingIncrementis 1,IndexSequencepresents indices in forward order (original). When thesamplingOffsetis -1 and thesamplingIncrementis -1,IndexSequencegenerates indices in reverse order (retrograde). -
UsageMode.SAMPLES_SHUFFLEDalso stores driver values obtained from an external source, but shuffles their presentation order at the beginning of each new cycle. I personally would not consider using this mode. In practice,samplingOffsetshould always be 0, whilesamplingIncrementshould always be 1.
Profile
Figure 1 illustrates four examples of DriverSequence
output with sequences of 96 samples generated. All four examples were generated with 8 cycles, each with 12 samples. The random seed was 2,
which produced a prettier shape for UsageMode.SAMPLE_DIRECT
than seed value 1.
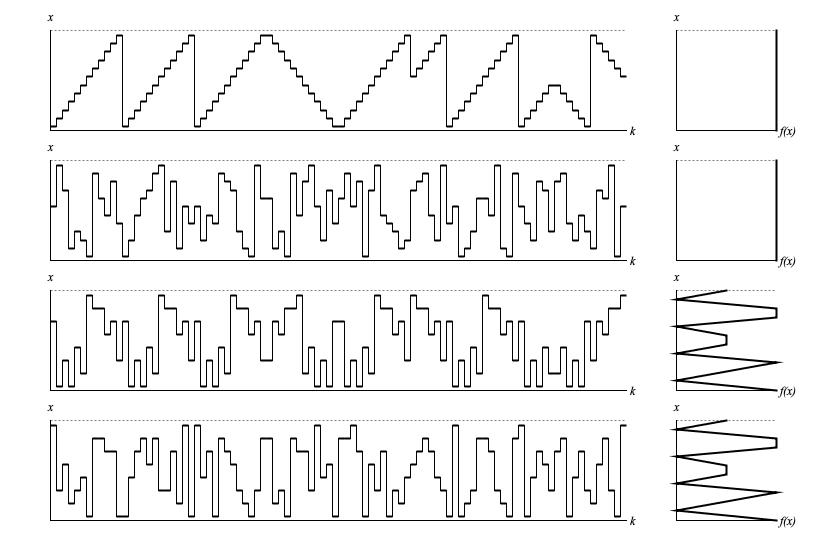
Figure 1: Sample output from
DriverSequence.next() with
different usage modes. The left
graph in each row displays samples in time-series while the right graph in the same row presents a histogram analyzed from the same samples.
The vertical x axes for the two graphs in each row represent the driver domain from zero to unity; the horizontal k axis of the time-series graph (left) plots ordinal sequence numbers; the horizontal f(x) axis of the histogram (right) plots the relative concentration of samples at each point in the driver domain.
The topmost graph was generated with UsageMode.UNIQUE_DIRECT.
The stored collection was populated with 12 values equally spaced between zero and unity.
The first three cycles employed a sampling offset of 0 (start with leftmost stored value) and a sampling increment of 1 (advance rightward by single elements).
The fourth cycle employed offset -1 (start with rightmost stored value) and increment of -1 (advance leftward by single elements).
The fifth cycle reprised offset 0 and increment 1.
The sixth and seventh cycle employed offset 5 (start with rightmost value in first half of collection) and increment -1 (advance leftward by single elements).
The eighth and final cycle employed offset 6 (start with second half of collection) and increment 1 (advance rightward by single elements).
The histogram on the far right was generated with a granualarity equal to the collection length. Since collection values are equally spaced, and
since each stored value occurs a total of eight times during the overall sequence, the histogram flatlines.
The second-from graph was generated with UsageMode.UNIQUE_SHUFFLE.
The stored collection was also populated with 12 values equally spaced between zero and unity; however this mode shuffles the order of these
values at the beginning of each cycle. Although this presentation order changes, it remains true that each stored value occurs a total of eight times
during the overall sequence. Hence the histogram flatlines for this sequence as well.
The third-from-top graph was generated with UsageMode.SAMPLE_DIRECT.
Here an array containing the values {0, 0, 1, 2, 2, 3, 4, 5, 5, 6, 6, 7} was shuffled giving
{5, 0, 2, 0, 3, 1, 7, 6, 6, 4, 5, 2}, then descaled to produce values equally spaced between zero and unity.
The first three cycles employed a sampling offset of 0 (start with leftmost stored value) and a sampling increment of 1 (advance rightward by single elements).
The fourth cycle employed offset -1 (start with rightmost stored value) and increment of -1 (advance leftward by single elements).
The fifth cycle reprised offset 0 and increment 1.
The sixth and seventh cycle employed offset 5 (start with rightmost value in first half of collection) and increment -1 (advance leftward by single elements).
The eighth and final cycle employed offset 6 (start with second half of collection) and increment 1 (advance rightward by single elements).
This time around the histogram granualarity remains at 12 but the number of distinct values has dropped to 8; thus, the histogram
drops to zero in four places. Also, since values 0, 2, 5, and 6 have duplicates each recurs sixteen times during the overall sequence, while values
1, 3, 4, and 7 only recur eight times. The histogram is by no means flat.
The bottommost graph was generated with UsageMode.SAMPLE_SHUFFLE.
Here the array containing the values {5, 0, 2, 0, 3, 1, 7, 6, 6, 4, 5, 2} was descaled to populate
the stored collection; however this original ordering is never seen because this mode shuffles the order at the beginning of each cycle.
In spite of the shuffling, it remains true that values 0, 2, 5, and 6 recur sixteen times, while values
1, 3, 4, and 7 only recur eight times. Thus the bottommost histogram exactly matches the third-from-top histogram.
Short-Term Uniformity
Output from DriverSequence, with
UsageMode.UNIQUE_SHUFFLE
selected, bears a particular relation to
Lehmer, which wraps Java's standard random number generator.
Output from both these drivers nominally follows a continuous uniform distribution;
however of the two, only DriverSequence realizes this distribution over the short term. In that
sense Lehmer is the continuous counterpart of the urn
model's selection with replacement, just as DriverSequence is one continuous counterpart
of selection without replacement.
This mode of output from DriverSequence is comparable to output from
Balance.
The difference is how these two drivers get to short-term uniformity. When the number of samples N making up a cycle or frame is known in advance,
UNIQUE_SHUFFLE will produce a sequence of samples which is
perfectly uniform, in the sense of having the flattest possible histogram. This is somewhat better than
Balance can achieve — though only somewhat.
Balance employs a quasi-deterministic algorithm which actively seeks to
place new samples in less-populated intervals. The nature of this algorithm is such that not only will an N-sample
frame be very nearly uniform, both the first and second halves of the frame will also be very nearly uniform. By contrast,
with DriverSequence in
UsageMode.UNIQUE_SHUFFLE
the halves of the frame will very likely not be uniform. For example, shuffling could place a preponderance of lower values
in the first half, then compensate with a preponderance of higher values in the second half.
When employing DriverSequence with the
UsageMode.UNIQUE_SHUFFLE
option selected, one should consider offsetting each sample with a random adjustment chosen uniformly between
−Δ/2 and +Δ/2, where
Δ = 1/N.
Externally Obtained Samples
UsageMode.SAMPLES_DIRECT
was devised to exploit externally obtained sequences, regardless of source. The exploitation of externally obtained
sequences has happened in at least two musical compositions that I know of: "Earth's Magnetic Field" by
Charles Dodge and "Canadian Coastlines" by
Larry Austin.
The challenge posed by externally obtained data is that of adapting values whose source range has nothing to
do with the internal purposes the values will be exploited for. Bringing this material into the
Driver/Transform model of selection means first descaling the source
values so that all elements in the descaled sequence have been shifted, squeezed, and/or stretched into the
driver domain from zero to unity. By abstracting out
the source range in this manner, a Transform
can be employed to map these descaled values to, for example, the range of a performing instrument.
Let N be the number of source samples, so that X0, X1, X2, …, XN-1 represent the original source values.
Suppose the extremes of the target range are themselves legitimate choices. This stipulation makes it reasonable to map the lowest source value to zero in the driver domain, which in turn will map to the minimum range value; likewise it is also reasonable to map the highest source value to unity in the driver domain, which in turn will map to the maximum range value. Discovering the lowest source value Xlow and the highest source value Xhigh is easily accomplished by iterating Xj over j. Once done the descaled value Yj can be derived using the calculation:
| Yj | = |
|
Suppose the extremes of the target range are not themselves legitimate choices. This happens for example with durational data where the minimum range value of 0 is not a valid duration and the range has no finite upper bound. A solution in this situation would be establish Δ = 1/N as padding. Here the lowest source value would map to 0 + Δ/2 in the driver domain, which in turn will map to higher than the range minimum; likewise the highest source value would map to 1 − Δ/2 in the driver domain, which in turn will map to lower than the range maximum. The calculation for the descaled value Yj then becomes:
| Yj | = |
|
+ Δ/2 |
DriverSequence implementation class.
Coding
The type hierarchy for DriverSequence is:
-
Sequence<T extends Number> extends WriteableEntity -
DriverSequence extends Sequence<Double> implements Driver
Most of the functionality in DriverSequence is actually implemented
by the Sequence base class.
The life cycle of a DriverSequence instance has three phases:
Construction, Population, and Consumption:
-
Construction allocates the instance
using
new DriverSequence(). -
Population brings values into
the embedded collection of
Doubleelements namedvalues. During this phase, successive calls toaddValue()append additionalDoubleelements to the collection. TheaddValue()method verifies that each element ranges from zero to unity.
When themodeisUsageMode.UNIQUE_DIRECTorUsageMode.UNIQUE_SHUFFLE, each additionalDoubleelement must be strictly greater than its predecessor. Among other things this prevents duplicateDoubleelements. A tolerance of .0000001 guides the determination of whether two values duplicate one another. -
Consumption happens in cycles. Each cycle begins with a call to
reset(). This call begins a preparation stage which establishes specific features of the cycle. Then follows an iteration stage. Iteration begins with the first pair of calls tohasNext(), and — ifhasNext()returnstrue— tonext(). Iteration continues untilhasNext()returnsfalse.
When themodeisUsageMode.UNIQUE_SHUFFLEorUsageMode.SAMPLES_SHUFFLE, each call toreset()provokes a call toshuffleValues().
Once consumption has commenced, it is bad practice to make further calls to addValue()
without first calling clear(). The clear()
method empties out the values collection, establishing a clean slate.
These methods assist in the Population phase:
-
Method
fillValues(Double source[])populates thevaluescollection from an array. Calling the array version offillValues()only makes sense when the usage mode isUNIQUE_DIRECTorSAMPLES_DIRECT. -
Method
fillValues(List<Double> source[])populates thevaluescollection from ajava.util.List. Calling the list version offillValues()only makes sense when the usage mode isUNIQUE_DIRECTorSAMPLES_DIRECT. -
Method
fillAscending(int itemCount)populatesvalueswith the driver values starting with 0 + Δ/2, incremented by Δ, and ending with 1 - Δ/2, where Δ =1/itemCount. -
Method
autoFillValues(int itemCount, Driver generator)populatesvalueswithdoublevalues from zero to unity until eithergenerator.hasNext()returnsfalseoritemCountvalues have been appended. CallingautoFillValues()only makes sense when the usage mode isSAMPLES_DIRECT. -
Method
fillDescaledValues(Double source[], boolean aysmptotic)populatesvalueswith descaleddoublevalues from thesourcearray. There are two descaling options:-
When
aysmptoticisfalse, values are descaled so that the smallestsourcevalue maps to zero and the largestsourcevalue maps to unity. -
When
aysmptoticistrue, a padding value Δ =1/source.lengthis calculated. Values are descaled so that the smallestsourcevalue maps to 0 + Δ/2 and the largestsourcevalue maps to 1 - Δ/2.
fillDescaledValues()only makes sense when the usage mode isSAMPLES_DIRECT. -
When
-
Method
fillDescaledValues(List<Double> source, boolean aysmptotic)populatesvalueswith descaleddoublevalues from thesourcelist. There are two descaling options:-
When
aysmptoticisfalse, values are descaled so that the smallestsourcevalue maps to zero and the largestsourcevalue maps to unity. -
When
aysmptoticistrue, a padding value Δ =1/source.size()is calculated. Values are descaled so that the smallestsourcevalue maps to 0 + Δ/2 and the largestsourcevalue maps to 1 - Δ/2.
fillDescaledValues()only makes sense when the usage mode isSAMPLES_DIRECT. -
When
These methods assist in the preparation stage of the Consumption phase:
-
Method
setSamplingOffset(int samplingOffset)sets the starting value of the internal iteration index — that is, it controls which member is presented first. EachsamplingOffsetvalue applies a different rotation. To obtain the unrotated sequence, setsamplingOffsetto 0. Values other than 0 make no sense forUsageMode.UNIQUE_SHUFFLEorUsageMode.SAMPLES_SHUFFLE. Neither do values other than 0 make sense whenreset()is followed either by an explicit call toshuffleValues()orpermuteValues(Permutation permutation). -
Method
setSamplingIncrement(int samplingIncrement)controls how far the internal iteration index advances after each call tonext(). Reference the discussion of the Every Nth permutation category. This argument may not be zero, and it must be relatively prime with the length ofvalues. To obtain forward order, setsamplingIncrementto 1. To obtain reverse order, setsamplingIncrementto -1; also setsamplingOffsetto -1. Values other than 1 make no sense forUsageMode.UNIQUE_SHUFFLEorUsageMode.SAMPLES_SHUFFLE. Neither do values other than 1 make sense whenreset()is followed either by an explicit call toshuffleValues()orpermuteValues(Permutation permutation). -
Method
shuffleValues()shuffles the elements ofvaluesrandomly. This method makes sense only in conjunction withfillAscending(), with asamplingOffsetof 0, and with asamplingIncrementof 1. CallingshuffleValues()explicitly is bad practice, since thereset()method callsshuffleValues()automatically forUsageMode.UNIQUE_SHUFFLEorUsageMode.SAMPLES_SHUFFLE. -
Method
permuteValues(Permutation permutation)reorders the elements ofvaluesas directed bypermutation. This method makes sense only with asamplingOffsetof 0, and asamplingIncrementof 1. CallingpermuteValues()makes no sense when the usage mode isUNIQUE_SHUFFLEorSAMPLES_SHUFFLE.
| © Charles Ames | Page created: 2022-08-29 | Last updated: 2022-08-30 |