Articulated Proximity: Rosy1
Introduction
The Rosy driver implements an algorithm that decides for each bit whether
to retain the set/clear state from the previous sample value or to toss a coin. The decision is effected by a
random trial based on a retention rate (proportion of retained versus reselected bits).
Other drivers concerned with distances between consecutive samples include the
Brownian driver
and with others which are obviated by Brownian.
The backstory behind the Rosy driver is embarrasing. My earlier "Catalog of Sequence
Generators"1
wrongly presented this as an algorithm for 1/f noise, also
known as "pink" noise. The source of that error (not trying to shift blame, just to document provinence) was a pre-publication draft of
Computer Music, 1st edition, by Charles Dodge and Thomas Jerse. Trying to reconstruct the algorithm from my Catalog's
pseudo-code was proving difficult, so I pulled out my copy of "Computer Music", now in its 2nd
edition.2 And found something called
the Voss algorithm, which was not the same at all. The rub is, just because the original algorithm doesn't generate proper 1/f
noise doesn't mean the algorithm can't be useable as a driver. The name of the present Rosy
class reflects this backstory. (It's not exactly pink.) How it works probably differs from the prepublication Dodge & Jerse code, which I
no longer have.
Profile
Figure 1 (a) illustrates five examples of Rosy
output with a sequence of 200 samples generated. All five examples were generated using a random seed of 1, an initial value of
0.5, and a rolloff parameter of 1.5. The only difference is the
retention parameter, which varies as indicated.
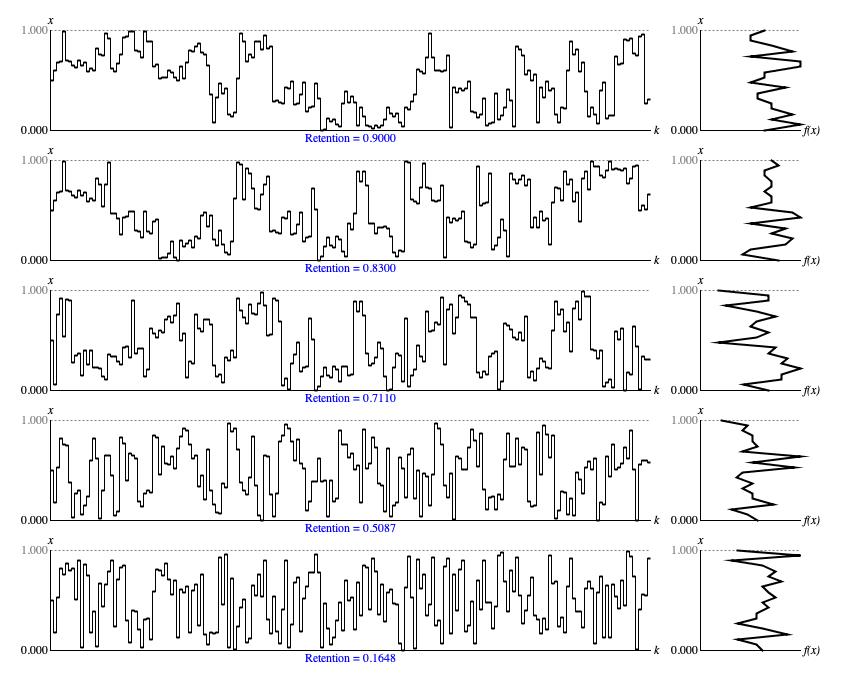
Figure 1: Sample output from
Rosy.next() with
representative retention settings. The left
graph in each row displays samples in time-series while the right graph in the same row presents a histogram analyzed from the same samples.
The vertical x axes for the two graphs in each row represent the driver domain from zero to unity; the horizontal k axis of the time-series graph (left) plots ordinal sequence numbers; the horizontal f(x) axis of the histogram (right) plots the relative concentration of samples at each point in the driver domain.
The most characteristic of the sequences in Figure 1 is the first, which has samples clustering in various regions of the driver domain.
As the retention parameter dials down to zero, the behavior comes to resemble uniform randomness (i.e., that produced by
Lehmer).
Bitwise Analysis
Figure 2 takes the sequence shown in Figure 1 and breaks out what happens in bit 1 (zero or one-half), bit 2 (zero or one-quarter), bit 3 (zero or one-eighth), bit 4 (zero or one-sixteenth), and the residual bits (continuous between zero and one-sixteenth).
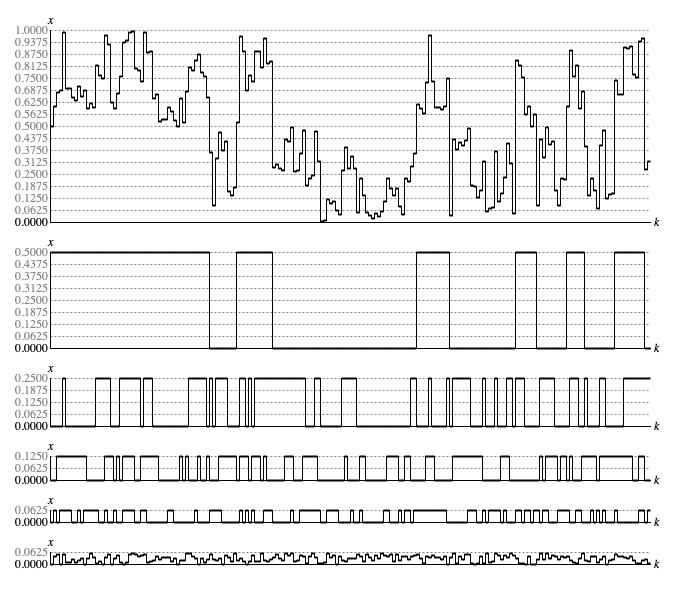
Figure 2: Bitwise analysis of a sequence generated by
Rosy.next().
The bit-specific graphs in Figure 2 transition back and forth between a set state (bit value 1) and a clear state (bit value 0).
Table 1 statistically analyses
of sample the actual stats for these bit-specific graphs. By comparison with the equivalent table for the
Lehmer driver, probability has shifted
away from single samples between transitions toward multiple samples between transitions.
| Transitions | 1 Sample | 2 Samples | 3 Samples | 4 Samples | 5 or more | |
|---|---|---|---|---|---|---|
| Actual Bit 1 | 12 | 8% | 91% | |||
| Actual Bit 2 | 50 | 30% | 12% | 14% | 12% | 32% |
| Actual Bit 3 | 59 | 32% | 16% | 16% | 6% | 27% |
| Actual Bit 4 | 80 | 34% | 20% | 8% | 8% | 10% |
Transitions
Figures 3 (a) through 3 (e) plot the range of sample-to-sample differences along the vertical Δx axis against the relative concentrations of these values along the horizontal f(Δx) axis.
Table 2 compares retention parameter settings with measured deviations for Δx around zero.
| Graph | Parametric Retention Setting | Actual Sample-to-Sample Deviation |
|---|---|---|
| Figure 3 (a) | 0.90 | 0.176 |
| Figure 3 (b) | 0.83 | 0.207 |
| Figure 3 (c) | 0.71 | 0.239 |
| Figure 3 (d) | 0.51 | 0.301 |
| Figure 3 (e) | 0.16 | 0.378 |
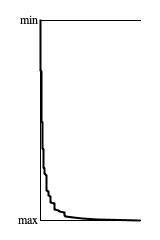
Figure 4: Divergence of 4-nibble pattern counts from
Rosy.next() with
retention 0.90 and rolloff 1.5 after 10,000 samples per pattern.
Independence
Figure 4 presents a trend graph of histogram tallies for 4-nibble patterns generated using
Rosy.next().
My analysis program decided to exclude low-frequency patterns by limiting the graph to the 8,192 largest tallies. The most frequent patterns were:
| 14 | 14 | 14 | 14 |
| 10 | 10 | 10 | 10 |
| 5 | 5 | 5 | 5 |
| 1 | 1 | 1 | 1 |
All of which had comparable tallies representing less than 1% presence. The distinguishing feature of these patterns is that they present the same value in sequence, which means that the output stayed within 1/16 of the driver domain for four consecutive samples. I don't believe there is anything special distinguishing these four patterns from any of the others that contributed to the bottom-most stair step in Figure 4.
The conclusion from Figure 4 is that the Rosy driver
fails the 4-nibble independence test.
Rosy implementation class.
Coding
The type hierarchy for Rosy is:
-
DriverBase extends WriteableEntityimplements Driver -
Rosy extends DriverBase
Listing 1 provides the source code for the Rosy
class. The sequential process described at the top of this page is implemented by
generate(), which is not public facing. Instead,
generate() is
called by DriverBase.next().
DriverBase.next() also
takes care to store the new sample in the field
DriverBase.value, where
generate() can employ
DriverBase.getValue() to pick this
(now previous) sample up for the next sample iteration.
DriverBase also offers
setValue() and randomizeValue()
methods to establish the initial sequence value.
Comments
- The present text corrects my Leonardo Music Journal article from 1992, "A Catalog of Sequence Generators". The heading is "1/f Noise", p. 63.
- Charles Dodge and Thomas Jerse, Computer Music: Synthesis, Composition, and Performance, 2nd edition, Schirmer, 1997, p. 368.
| © Charles Ames | Page created: 2022-08-29 | Last updated: 2022-08-30 |