Open Quarter-Tone Clusters
Introduction
The previous page explored ways of mitigating the harshness of tone clusters. Techniques included arpeggiation, open voicing, and formant filtering. In addition to mitigating the harshness of clusters; applying a technique in different ways made it possible to elaborate one original sound into multiple derived sounds. Where the original sound would uniformly emphasize all of the tones within a given range, the derived sounds would favor some tones over others. Thus the sparser sounds might hopefully enrich the palette of resources. However this benefit can fully be realized only if steps are taken to ensure that the derived sounds mutually complement one another. Indicating that two sounds complement one another can mean either that the two sounds contain different constituents or that the sounds emphasize common constituents differently. It also means that the differences are clearly audible to an unsophisticated listener.
The present page narrows the focus to quarter-tone clusters in open voicing. The first exercise, Complimentary Voicings seeks to enumerate a set of voicings which mutually complement one another. The second exercise, Shaded Voicings makes use of a parametrically driven weighting function to favor some tones over others. This first and second exercise are each illustrated by presenting a fixed-duration sequence of voicings, articulated according to a certain pattern. The third exercise, Shakes, explores what happens when voicings alternate rapidly, an effect analogous to traditional trills or tremolos.
Complimentary Voicings
The technique of open voicing begins with a cluster filling the octave with adjacent scale steps. It then distributes these scale steps over a range of multiple octaves. The tones of an open voicing do not saturate the range of the cluster; instead one-and-the-same scale step may be realized using two or more tones, so long as the number of tones per step remains consistent.
For the present exercise, two open cluster-voicings are said to be complementary if each voicing transitions well into the other. Complementary means that that the voicings are similar, in the sense that corresponding tones are nearby in pitch. Thus the transition produces no sense of discontinuity. Complementary also means that the voicings are contrasting in the sense that between corresponding tones, more pitches move than not, and that among the pitches that move, there is a preponderance neither of upward motions nor of downward motions.
Content Generation
Generating a palette of complementary cluster voicings is a knotty problem, one which I personally (and I suspect most others) am not capable of working through with pen and paper. Indeed, setting up the problem for solution using an AI constraint satisfaction search is not trivial. Implementing the search as a brute-force enumeration — that is, when all of the options available to a decision the search backtracks to the immediately preceding decision — got to no results within any reasonable amount of time. Adopting a more sophisticated approach which analyzed impasses and backtracked to sources of conflict, did eventually yield solutions, but even then took many hours.
I set things up using my production framework, subclassing my Problem class from HeuristicSearch, and mapping production entities to the object model as follows:
- The source cluster maps to the Problem.
- Each voicing of the source cluster maps to a Scaffold.
- Each tone within a voicing maps to a Decision
- Each pitch available to a tone maps to an Option.
The order of pitch-for-tone decisions under any voicing-scaffold was random. Three heuristic criteria affected the order of pitch options under any tone-decision: the count of other voicings employing the same pitch option for the same tone (coarse), the count of other tones in the same voicing employing the same microtonal step number (medium), and randomness (fine). Of these criteria, the first made the difference between searches which produced no solution after many hours and searches which produced solutions within minutes.
There are forty-eight tones per voicing (two instances each of the twenty-four steps in quarter-tone temperament) and seven pitch-options per tone (from three steps below the reference pitch to three steps above the reference pitch). The constraints for producing a valid voicing are that every quarter-tone step must appear exactly twice and that the order of pitch choices must follow the order of reference pitches (no ‘voice crossings’).
The constraints for ensuring that one voicing properly compliments any predecessor apply a limit of 2/5 the tone count (48×2/5=19). This limit applies to three quantities: the count of tones holding over between voicings, the count of tones ascending between voicings, and the count of tones descending between voicings. An additional constraint forbids parallel octaves.
Profile Generation
Running the search just described produced a supply of 5 mutually complimentary cluster voicings. Rather than presenting these voicings individually, I have elected to generate a sequence of 30 sounds, each chosen from the supply. The results appear below as Video 1. The example presented in Video 1 begins with a quarter second of silence, presents eight seconds of sound, then ends with an additional quarter second of silence. The eight seconds of sound divide into 64 moments lasting 0.125 seconds each. All moments divide into transition phase and steady-state phases. Some moments are preceded by silences whose time is appropriated from the previous moment's steady-state phase.
Voicings were selected using a HeuristicSearch Selection of voicings was guided by the equal-emphasis principle, subject to the constraint that no specific voicing may follow itself. Thus moments 1-5 employ all five voicings in the order E, D, C, B, A; moments 6-10 employ all five voicings in the order D, C, B, E, A; and so forth.
| Moment | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Articulation | • | ~ | > | ~ | > | ~ | ~ | • | ~ | > | ~ | > | ~ | > | ~ | ~ | • | > | > | ~ | ~ | • | > | > | > | ~ | ~ | > | ~ | • |
| Voicing | E | D | C | B | A | D | C | B | E | A | D | C | B | E | A | C | D | B | E | A | D | C | B | E | A | D | C | B | E | A |
Video 1: Sequence of complimentary cluster voicings. Figure 1: Rhythmic sequence 2+2+3 2+2+2+3 1+1+3 1+1+1+3+2 1 realized as sequence of complimentary cluster voicings.
Shaded Voicings
Shaded Content
The previous heading specifically applied the technique of open voicing to quarter-tone clusters, and also took active steps to ensure that the members in any pair of voicings would not sound too much alike.
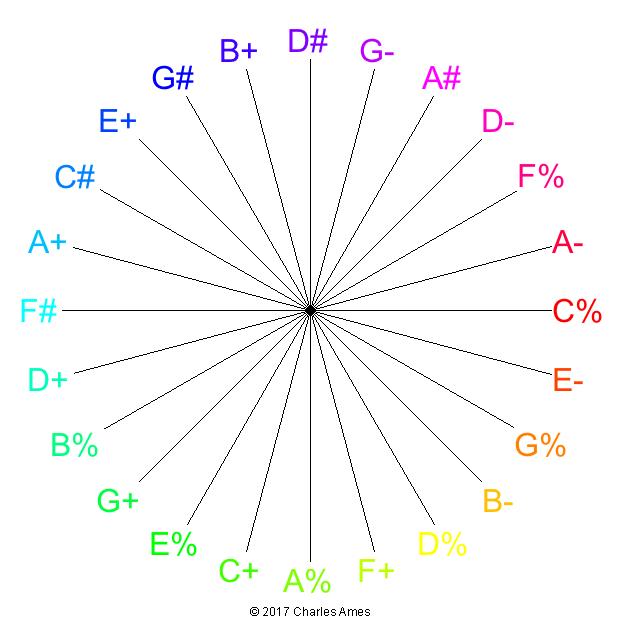
The circle in Figure 2 enumerates the 24 steps of quarter-tone temperament. Notation follows my implementation of
the Ashton score-transcription utility: The white notes on the piano are indicated using the letters A through G.
A percent sign (%) indicates a natural. A pound sign (#) indicates a semitone sharp. An exclamation point (!)
indicates a semitone sharp. A plus sign (+) indicates a 50-cent inflection upward. A minus sign (+) indicates a 50-cent inflection
downward.
The circle in Figure 2 has the following properties.
- Each of the 24 steps of quarter-tone temperament appears exactly once.
-
Every twelve consecutive steps in the circle forms a scale of the form
C% C# D- D# E+ F% G- G# A- A+ A# B+, where the intervals expressed as fractions of a whole tone are 2/4, 1/4, 3/4, 3/4, 1/4, 1/4, 3/4, 1/4, 2/4, 1/4, 3/4, (1/4). This scale ‘fills’ the octave with no interval wider than 3/4 of a tone. -
Every seven consecutive steps in the circle forms a scale of the form
C% D- D# F% G- A- A#, where the intervals expressed as fractions of a whole tone are 3/4, 3/4, 4/4, 3/4, 4/4, 3/4, (4/4). This scale ‘fills’ the octave with no interval smaller than one and a half semitones and no interval wider than a whole tone.
What is desired is a function to control the relative amplitude of each quarter-tone step, with largest amplitudes at a reference point and smallest amplitudes on the reference's opposing point. One suitable function1 is
| Wm = β0.5*cos[θ(m,s)] , | (Expression 1) |
where
|
(Expression 2) |
Here m is the circle position (0 ≤ m < 24); for examples, m = 0 indicates C%, m = 1 indicates A-, and so forth. β is the max/min weight ratio, which must be positive. s locates the maximum weight around the circle in Figure 2 (0 ≤ s < 1); for examples, s = 0/24 = 0 locates the maximum weight over C%, while s = 6/24 = 0.25 locates the maximum weight over D#.
Here's how the function works:
- When θ is 0°, cos(θ) is 1, giving a maximum amplitude of β0.5cos(θ) = β0.5 = √β.
- When θ is 90°, cos(θ) is 0, giving an intermediate amplitude of β0.5cos(θ) = β0 = 1.
- When θ is 180°, cos(θ) is -1, giving a minimum amplitude of β0.5cos(θ) = β-0.5 = 1/√β.
- When θ is 270°, cos(θ) is again 0, giving the intermediate amplitude β0.5cos(θ) = β0 = 1.
- The max/min weight ratio is √β ÷ 1/√β = √β × √β = β.
The next two animations demonstrate this weighting function in action. Each animation presents two perspectives simultaneously. The graphic on the left side plots the weighting function as a band whose thickness increases with weight. The graphic on the right side plots amplitudes of individual tones.
Video 2: Sequence of complimentary clusters.
The animation shown in figure Video 2 illustrates the continuity of sounds obtainable by varying the location parameter s in Expression 1 and Expression 2. This animation presents a single sound with the max/min ratio β parameter fixed at 12. The location parameter s proceeds through two full rotations around the circle.
Video 3: Sequence of complimentary clusters.
The animation shown in figure Video 3 illustrates percussive sounds obtained by sweeping the max/min ratio β from unity (all scale steps emphasized equally) to 12. Five different sounds are presented, representing s values of 0.0, 0.4, 0.8, 0.2, and 0.6 respectively.
Shaded Profile
Video 3.
Figure 4: Rhythmic sequence 2+2+3 2+2+2+3 1+1+3 1+1+1+3+2 1
realized locally by changed voicings and regionally by changed shadings.
Shakes
Video 4: Shake material: (a) array A with 0.0 shading, (b) array B with 0.0 shading, (c) array A with 0.2 shading, (d) array B
with 0.2 shading.
Video 5: Modes of shaking: (a) voicing and shading, (b) only shading, (c) only voicing, (d) alternations.
Comments
-
This is the same function illustrated on p. 39 of my 1986 article
“Two Pieces for Amplified Guitar”.
© Charles Ames
Page created: 2017-08-15
Last updated: 2017-08-15
Figure 4: Rhythmic sequence 2+2+3 2+2+2+3 1+1+3 1+1+1+3+2 1 realized locally by changed voicings and regionally by changed shadings.
Video 4: Shake material: (a) array A with 0.0 shading, (b) array B with 0.0 shading, (c) array A with 0.2 shading, (d) array B with 0.2 shading.
Video 5: Modes of shaking: (a) voicing and shading, (b) only shading, (c) only voicing, (d) alternations.
| © Charles Ames | Page created: 2017-08-15 | Last updated: 2017-08-15 |